SU_Checkin
这是一道签到题。
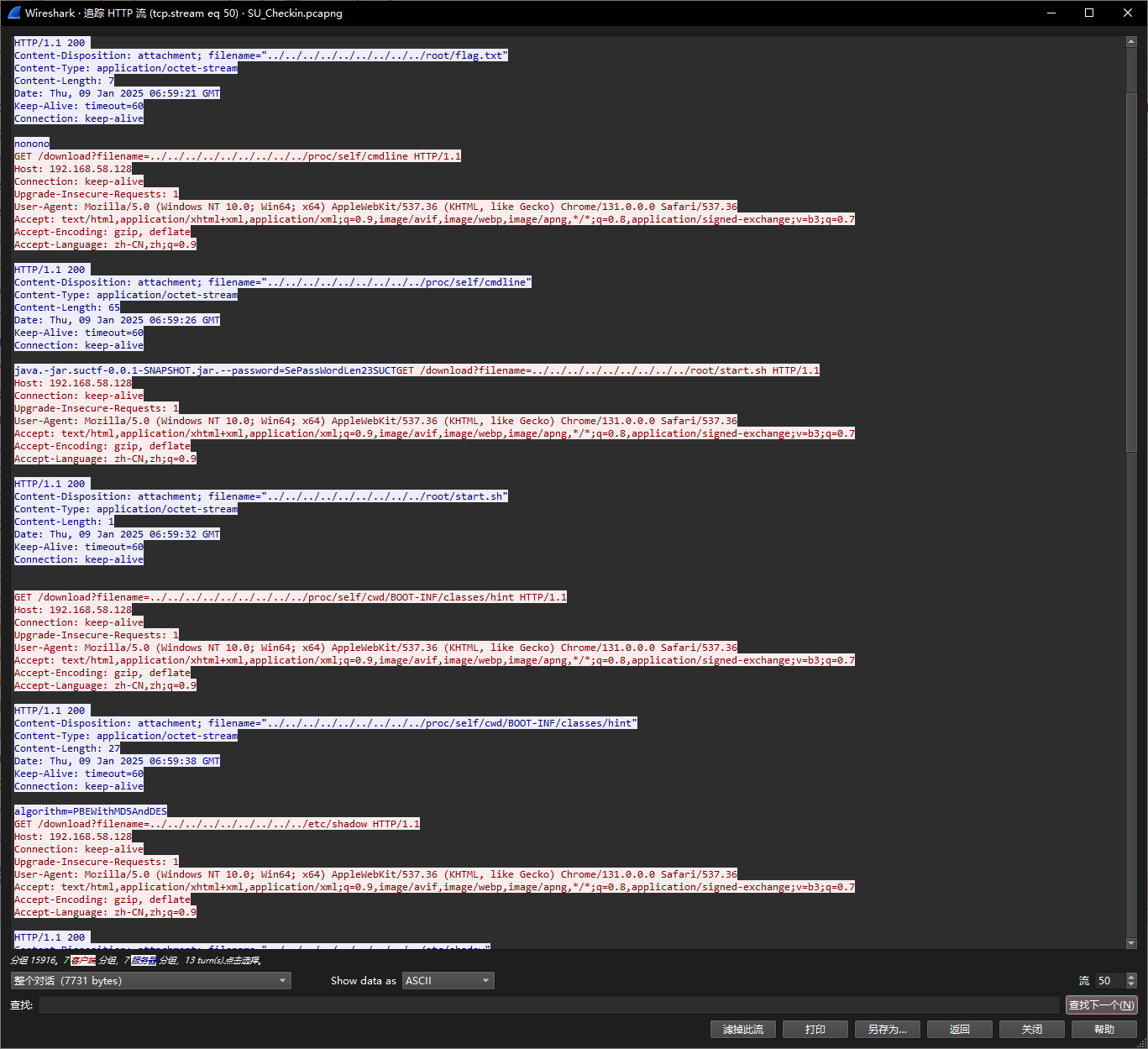
搜索flag得到流50
得到几个关键信息
1 java.-jar.suctf-0.0.1-SNAPSHOT.jar.--password=SePassWordLen23SUCT
1 algorithm=PBEWithMD5AndDES
1 OUTPUT=ElV+bGCnJYHVR8m23GLhprTGY0gHi/tNXBkGBtQusB/zs0uIHHoXMJoYd6oSOoKuFWmAHYrxkbg=
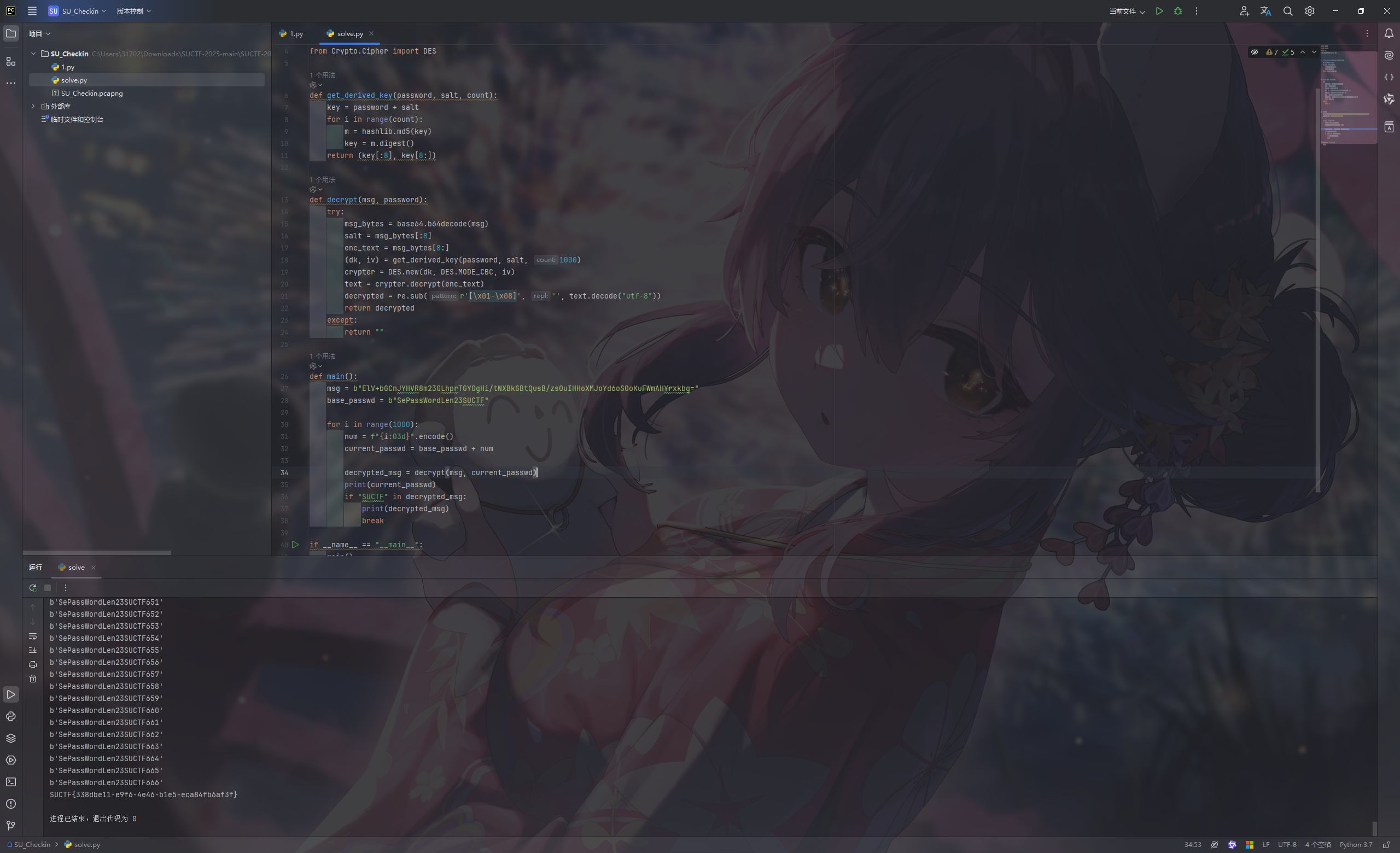
套脚本,手动补上爆破逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import base64import hashlibimport refrom Crypto.Cipher import DESdef get_derived_key (password, salt, count ): key = password + salt for i in range (count): m = hashlib.md5(key) key = m.digest() return (key[:8 ], key[8 :]) def decrypt (msg, password ): try : msg_bytes = base64.b64decode(msg) salt = msg_bytes[:8 ] enc_text = msg_bytes[8 :] (dk, iv) = get_derived_key(password, salt, 1000 ) crypter = DES.new(dk, DES.MODE_CBC, iv) text = crypter.decrypt(enc_text) decrypted = re.sub(r'[\x01-\x08]' , '' , text.decode("utf-8" )) return decrypted except : return "" def main (): msg = b"ElV+bGCnJYHVR8m23GLhprTGY0gHi/tNXBkGBtQusB/zs0uIHHoXMJoYd6oSOoKuFWmAHYrxkbg=" base_passwd = b"SePassWordLen23SUCTF" for i in range (1000 ): num = f"{i:03d} " .encode() current_passwd = base_passwd + num decrypted_msg = decrypt(msg, current_passwd) print (current_passwd) if "SUCTF" in decrypted_msg: print (decrypted_msg) break if __name__ == "__main__" : main()
SU_forensics
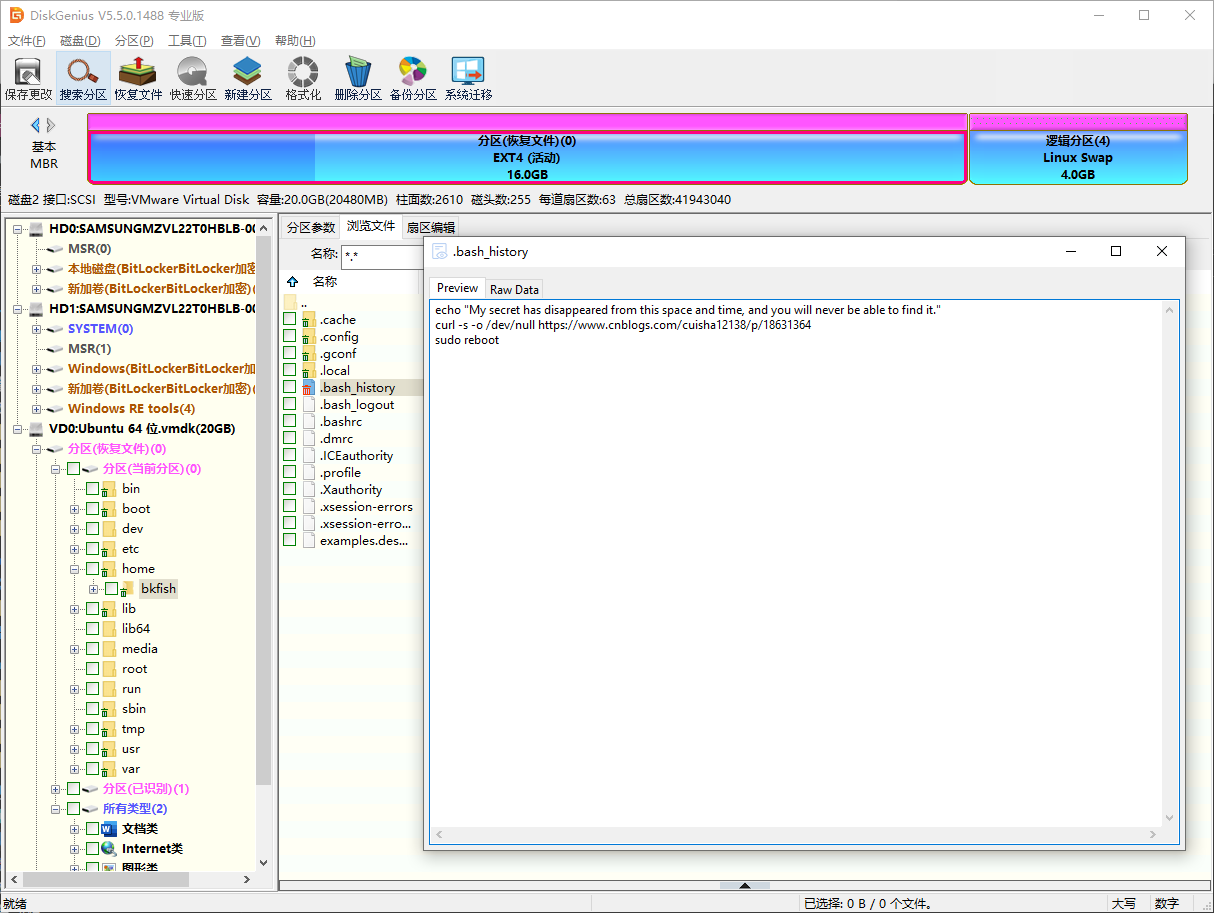
bkfish在自己的虚拟机里运行了某些命令之后用”sudo reboot”重启了主机,接着他按照网上清除入侵记录的方法先”rm -rf .bash_history”然后”history -c”删除了所有的命令记录。
在现实世界中,消失的东西就找不回来了,但在网络世界里可未必如此,你能找到bkfish消失的秘密吗?
flag提交格式:全大写的SUCTF{XXXX}
附件链接:https://pan.baidu.com/s/1v_HcyaFZLSzCV2A4WrjrLA?pwd=cdcp https://1drv.ms/u/c/6de0e327b7a135f3/EVx4BxJ6beZJl8tMStRZhgYBKM0EE3vgbSVHx_6fImJFRQ?e=vFAN1U
After running some commands in his virtual machine, bkfish restarted the host with “sudo reboot”. Then he followed the method of clearing intrusion records on the Internet, first “rm -rf .bash_history” and then “history -c” to delete all command records.
In the real world, things that disappear can never be found again, but this may not be the case in the online world. Can you find bkfish’s lost secret?
Flag submission format: all uppercase SUCTF{XXXX}
Attachment link:https://pan.baidu.com/s/1v_HcyaFZLSzCV2A4WrjrLA?pwd=cdcp https://1drv.ms/u/c/6de0e327b7a135f3/EVx4BxJ6beZJl8tMStRZhgYBKM0EE3vgbSVHx_6fImJFRQ?e=vFAN1U
数据恢复题
1 2 echo "My secret has disappeared from this space and time, and you will never be able to find it." curl -s -o /dev/null https://www.cnblogs.com/cuisha12138/p/18631364
访问对应网页
根据hint想到网站快照
使用Wayback Machine
Wayback Machine
得到secret - testttt-su - 博客园
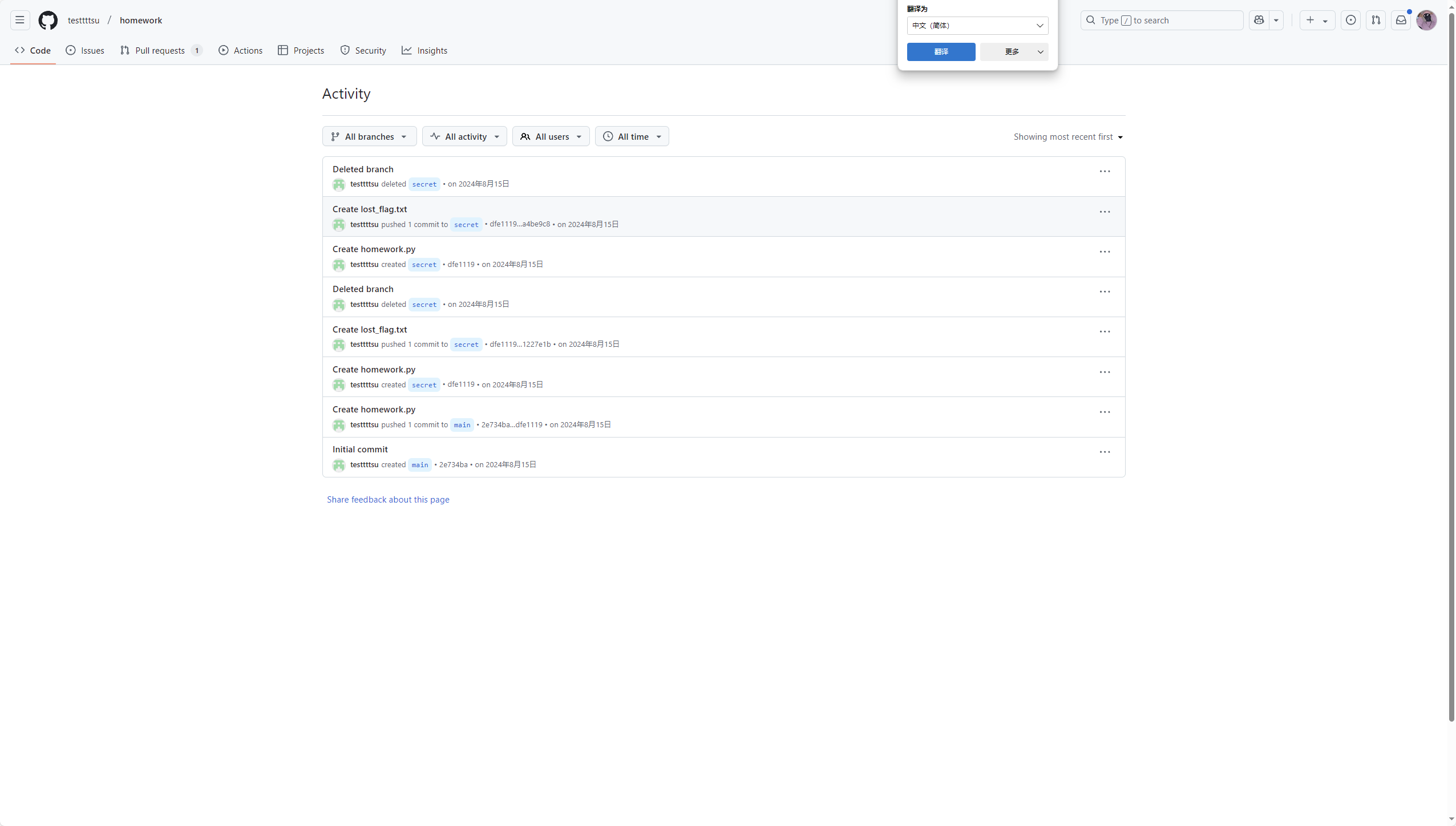
找到testtttsu/homework
发现对应分支已被删除
想到安全研究员强调,已删除的GitHub数据仍可被访问
而图片里给了三位a4b
这里可以写脚本爆破
这里抄wp爆破脚本了
SUCTF 2025 Writeup by 0xFFF ::
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 import requestsimport timeimport randomimport stringfrom requests.adapters import HTTPAdapterfrom urllib3.util.retry import Retryclass GitCommitChecker : def __init__ (self, base_url, retries=5 , timeout=10 ): self.base_url = base_url self.session = self.create_session(retries) self.timeout = timeout def create_session (self, retries ): """Create and configure the requests session.""" session = requests.Session() retry_strategy = Retry( total=retries, backoff_factor=0.5 , status_forcelist=[429 , 500 , 502 , 503 , 504 ], ) session.mount('http://' , HTTPAdapter(max_retries=retry_strategy)) session.mount('https://' , HTTPAdapter(max_retries=retry_strategy)) return session def check_commit (self, commit_hash ): """Check if the commit exists by sending a HEAD request.""" url = f"{self.base_url} /commit/{commit_hash} " try : response = self.session.head(url, timeout=self.timeout) if response.status_code == 200 : print (f"Valid commit found: {url} " ) return True except requests.exceptions.RequestException as e: print (f"Error with commit {commit_hash} : {e} " ) return False def generate_hashes (self ): """Generate hash combinations to be tested.""" hex_chars = string.hexdigits.lower() for part1 in hex_chars: for part2 in hex_chars: for part3 in hex_chars: for part4 in hex_chars: yield f"{part1} {part2} {part3} {part4} " def find_commit (self, skip_hash="6129" ): """Try to find the valid commit hash.""" for commit_hash in self.generate_hashes(): if commit_hash == skip_hash: continue print (f"Trying hash: {commit_hash} " ) if self.check_commit(commit_hash): return commit_hash time.sleep(0.2 ) return None def main (): base_url = "https://github.com/testtttsu/homework" checker = GitCommitChecker(base_url) found_commit = checker.find_commit() if found_commit: print (f"Suspicious commit found: {found_commit} " ) else : print ("No suspicious commit found." ) if __name__ == "__main__" : main()
或者可以直接访问https://github.com/testtttsu/homework/activity->这个好
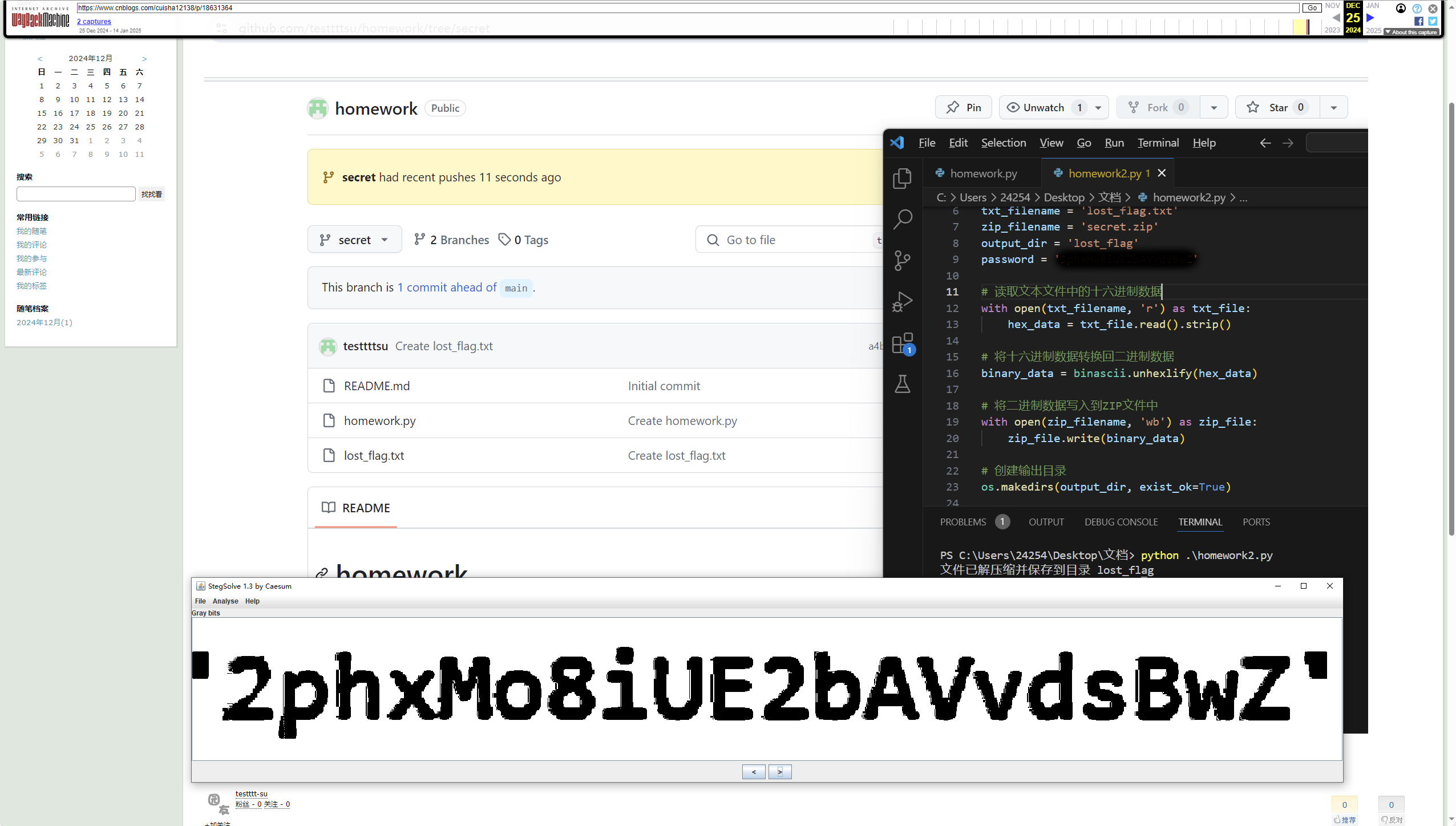
密码在图片里 放大就能看见
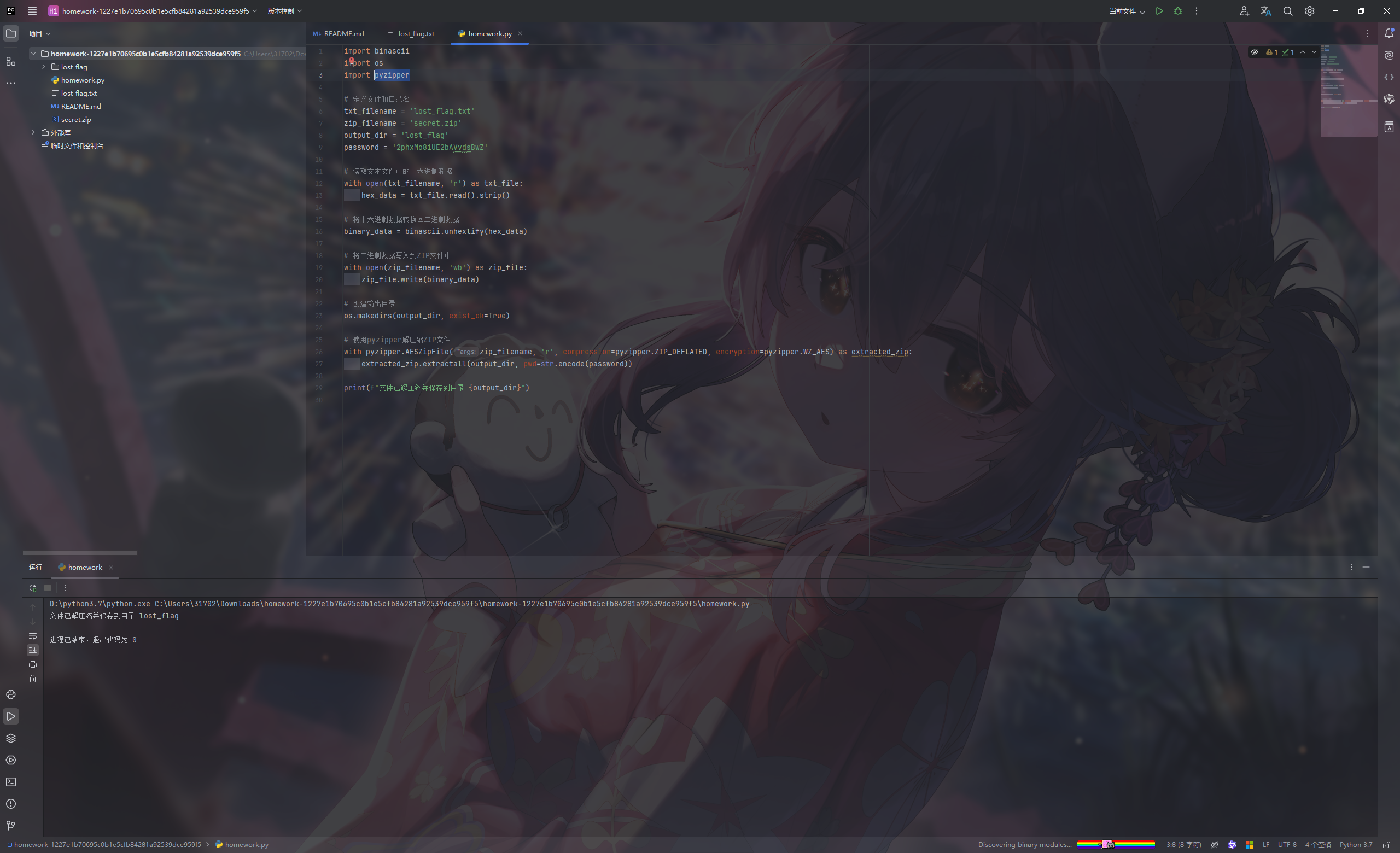
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import binasciiimport osimport pyzippertxt_filename = 'lost_flag.txt' zip_filename = 'secret.zip' output_dir = 'lost_flag' password = '2phxMo8iUE2bAVvdsBwZ' with open (txt_filename, 'r' ) as txt_file: hex_data = txt_file.read().strip() binary_data = binascii.unhexlify(hex_data) with open (zip_filename, 'wb' ) as zip_file: zip_file.write(binary_data) os.makedirs(output_dir, exist_ok=True ) with pyzipper.AESZipFile(zip_filename, 'r' , compression=pyzipper.ZIP_DEFLATED, encryption=pyzipper.WZ_AES) as extracted_zip: extracted_zip.extractall(output_dir, pwd=str .encode(password)) print (f"文件已解压缩并保存到目录 {output_dir} " )
再用同样的密码解压压缩包2phxMo8iUE2bAVvdsBwZ
得到
有 27 种符号,假设是 26 个字母加空格。写代码对图像进行切块识别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 from PIL import Imageimport numpy as npimport osdef crop_symbols (image, symbol_width, symbol_height ): """ 从拼接图片中切割出每个符号。 """ img_width, img_height = image.size symbols = [] for y in range (0 , img_height, symbol_height): row = [] for x in range (0 , img_width, symbol_width): box = (x, y, x + symbol_width, y + symbol_height) cropped = image.crop(box).convert('L' ) row.append(cropped) symbols.append(row) return symbols def generate_templates (symbols, max_templates=28 ): """ 自动生成模板:将符号进行分类,挑选出指定数量的不同符号。 """ templates = {} template_index = 0 for row in symbols: for symbol in row: symbol_array = np.array(symbol) matched = False for char, template in templates.items(): template_array = np.array(template) diff = np.sum ((symbol_array - template_array) ** 2 ) if diff < 1000 : matched = True break if not matched: char = chr (ord ('a' ) + template_index) if template_index < 26 else ('+' if template_index == 26 else '{' ) templates[char] = symbol template_index += 1 if template_index >= max_templates: break if template_index >= max_templates: break return templates def match_symbol (cropped_symbol, templates ): """ 匹配单个符号到模板。 """ cropped_array = np.array(cropped_symbol) best_match = None min_diff = float ('inf' ) for char, template in templates.items(): template_array = np.array(template.resize(cropped_symbol.size)) diff = np.sum ((cropped_array - template_array) ** 2 ) if diff < min_diff: min_diff = diff best_match = char return best_match def recognize_image (image_path, symbol_width, symbol_height ): """ 主函数:识别图片,并输出每行符号值。 """ image = Image.open (image_path).convert('L' ) symbols = crop_symbols(image, symbol_width, symbol_height) print ("Generating templates..." ) templates = generate_templates(symbols, max_templates=28 ) print ("Generated templates:" ) for char, template in templates.items(): template.save(f'template_{char} .png' ) print (f"Template for {char} saved as template_{char} .png" ) result = [] for row in symbols: row_result = '' .join(match_symbol(symbol, templates) for symbol in row) result.append(row_result) return result if __name__ == "__main__" : image_path = "lost_flag.png" symbol_width = 138 symbol_height = 108 results = recognize_image(image_path, symbol_width, symbol_height) for i, line in enumerate (results): print (line)
得到
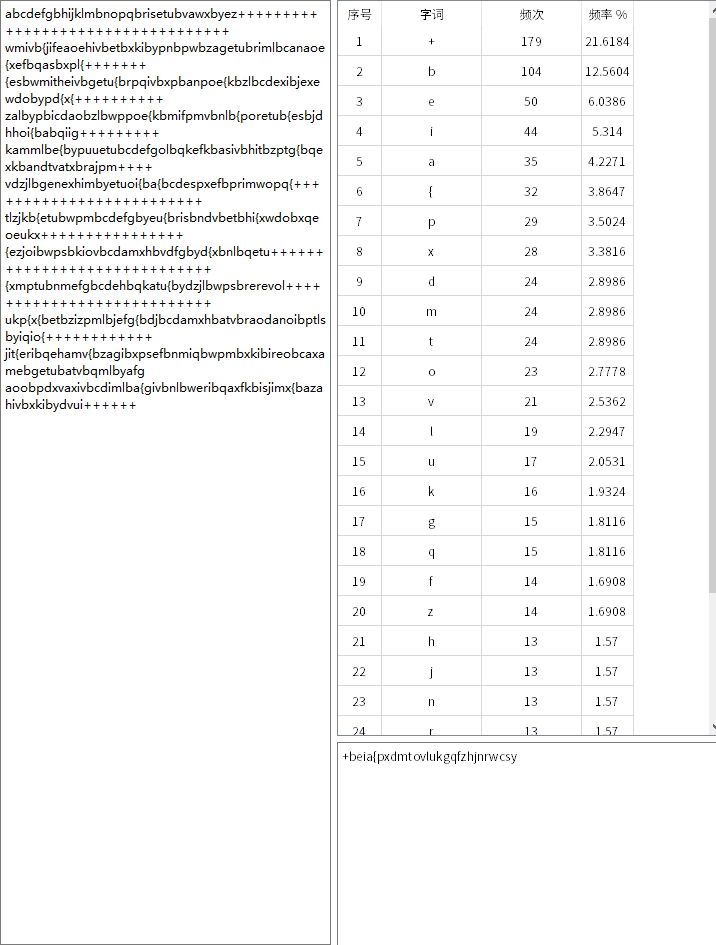
1 2 3 4 5 6 7 8 9 10 11 12 abcdefgbhijklmbnopqbrisetubvawxbyez++++++++++++++++++++++++++++++++++ wmivb{jifeaoehivbetbxkibypnbpwbzagetubrimlbcanaoe{xefbqasbxpl{+++++++ {esbwmitheivbgetu{brpqivbxpbanpoe{kbzlbcdexibjexewdobypd{x{++++++++++ zalbypbicdaobzlbwppoe{kbmifpmvbnlb{poretub{esbjdhhoi{babqiig+++++++++ kammlbe{bypuuetubcdefgolbqkefkbasivbhitbzptg{bqexkbandtvatxbrajpm++++ vdzjlbgenexhimbyetuoi{ba{bcdespxefbprimwopq{+++++++++++++++++++++++++ tlzjkb{etubwpmbcdefgbyeu{brisbndvbetbhi{xwdobxqeoeukx++++++++++++++++ {ezjoibwpsbkiovbcdamxhbvdfgbyd{xbnlbqetu+++++++++++++++++++++++++++++ {xmptubnmefgbcdehbqkatu{bydzjlbwpsbrerevol+++++++++++++++++++++++++++ ukp{x{betbzizpmlbjefg{bdjbcdamxhbatvbraodanoibptlsbyiqio{++++++++++++ jit{eribqehamv{bzagibxpsefbnmiqbwpmbxkibireobcaxamebgetubatvbqmlbyafg aoobpdxvaxivbcdimlba{givbnlbweribqaxfkbisjimx{bazahivbxkibydvui++++++
统计词频发现b明显多,猜测为空格或什么标点
将b替换为空格
1 2 3 4 5 6 7 8 9 10 11 12 abcdefgbhijklmbnopqbrisetubvawxbyez wmivb{jifeaoehivbetbxkibypnbpwbzagetubrimlbcanaoe{xefbqasbxpl{ {esbwmitheivbgetu{brpqivbxpbanpoe{kbzlbcdexibjexewdobypd{x{ zalbypbicdaobzlbwppoe{kbmifpmvbnlb{poretub{esbjdhhoi{babqiig kammlbe{bypuuetubcdefgolbqkefkbasivbhitbzptg{bqexkbandtvatxbrajpm vdzjlbgenexhimbyetuoi{ba{bcdespxefbprimwopq{ tlzjkb{etubwpmbcdefgbyeu{brisbndvbetbhi{xwdobxqeoeukx {ezjoibwpsbkiovbcdamxhbvdfgbyd{xbnlbqetu {xmptubnmefgbcdehbqkatu{bydzjlbwpsbrerevol ukp{x{betbzizpmlbjefg{bdjbcdamxhbatvbraodanoibptlsbyiqio{ jit{eribqehamv{bzagibxpsefbnmiqbwpmbxkibireobcaxamebgetubatvbqmlbyafg aoobpdxvaxivbcdimlba{givbnlbweribqaxfkbisjimx{bazahivbxkibydvui
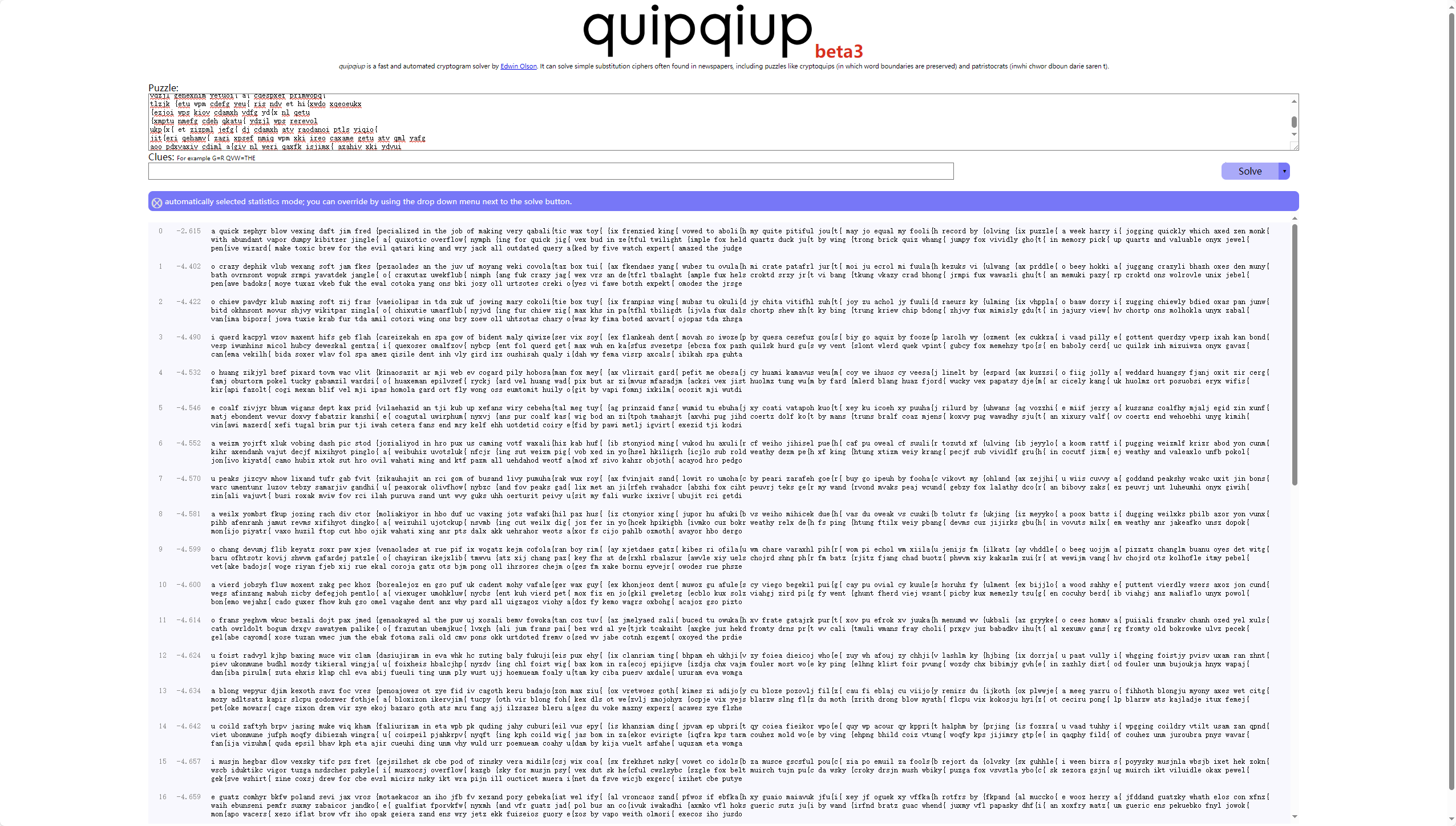
quipqiup - cryptoquip and cryptogram solver 得到
1 2 3 4 5 6 7 8 9 10 11 12 a quick zephyr blow vexing daft jim fred specialized in the job of making very qabalistic wax toys six frenzied kings vowed to abolish my quite pitiful jousts may jo equal my foolish record by solving six puzzles a week harry is jogging quickly which axed zen monks with abundant vapor dumpy kibitzer jingles as quixotic overflows nymph sing for quick jigs vex bud in zestful twilight simple fox held quartz duck just by wing strong brick quiz whangs jumpy fox vividly ghosts in memory picks up quartz and valuable onyx jewels pensive wizards make toxic brew for the evil qatari king and wry jack all outdated query asked by five watch experts amazed the judge
从gpt回答不难发现每一行豆少了一个字母 拼接即可
得到最终答案